機械学習の初心者がAirbnbのリスク管理について調べてみた
Airbnbというサービスをご存知でしょうか?
世界中の魅力的な家に泊まれてしまう素敵なサービスです。サンフランシスコ生まれ(育ち?)のスタートアップ企業が提供しています。
素敵なサービスですが、見ず知らずの人の家に見ず知らずの人が泊まることができるので、安全面どうなんだろう?とちょっと気になるサービスでもあります。
宿泊先で事件が起きたりすると、信用面でビジネスへのダメージは大きいです。その辺のリスク管理が重要なサービスだと思います。
リスク管理に機械学習を利用
安心して宿泊先を登録・利用してもらうため、Airbnbではリスク管理の一部に機械学習を利用しているようです。
機械学習が利用されるシーンとしては、例えば
- 特定の地域で、普段の10倍の予約があった場合、詐欺の可能性が高いので検知してフィルタにかける。
- クレジットカードの払い戻し要求の詐欺を検知する。
といったことに利用されているようです。
Airbnbのスコアリングフレームワーク
詐欺の手口は巧妙化してきているため、様々なケースを柔軟に追加できるアーキテクチャが要求されます。Airbnbでは下記のアーキテクチャで実現しているようです。
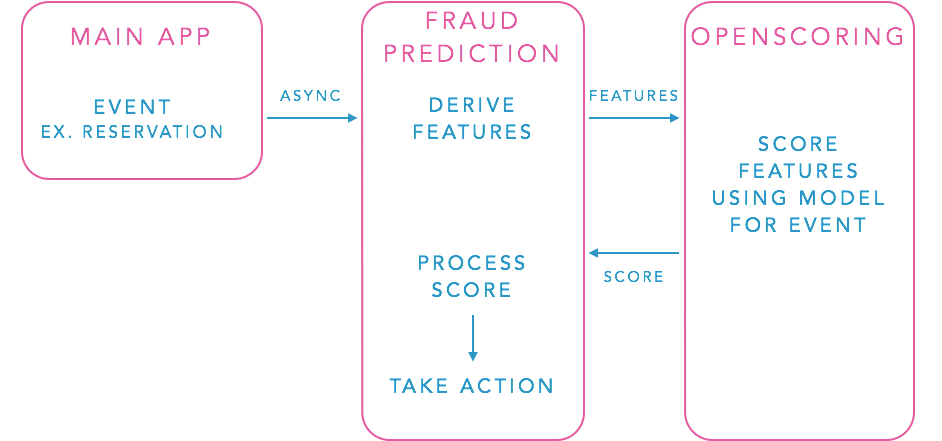
ユーザーが宿泊先の予約を作成した場合の流れを例に説明します。
MAIN APP(Aribnbのアプリ本体)
宿泊先の予約が発生したら、FRAUD PREDICTION(詐欺検知)にクエリを投げる。
FRAUD PREDICTION(詐欺検知)
「予約作成」のモデルに対して、検証用データを作成してOPENSCORING(機械学習を利用したデータの検証ロジック)に投げる。このときの検証用データとしては、どの場所でどのタイミングでどういった人が予約したか?そのときの周りの状況はどうか?といった内容だと思われます。負荷軽減のために、クエリの非同期化、DBリクエストの並列化などを行っているようです。
OPENSCORING(機械学習を利用したデータの検証ロジック)
受け取った検証用データをもとに、その検証スコアと、設定した閾値による判定(詐欺か、通常のユーザーか)をFRAUD PREDICTIONに返す。FRAUD PREDICTIONは、受け取った判定をもとにアクションをする。(例えば、詐欺であれば予約を差し止めるなど。)
ここではJSON REST形式のJavaのライブラリ(JPMML:Java Predictive Model Markup Language )が使われています。Predictive Model Markup Language (PMML)とは、Data Mining Groupが策定した、異なるデータマイニング製品間で分析モデルの交換・共有を可能にするXMLベースの言語です。PMMLについては、この辺のブログがわかりやすかったです。サポートしている機械学習のロジックとしては、tree models, logit models, SVMs, neural networks などで、Airbnbではrandom forests, kafka logging, statsd monitoringなどを利用しているようですが、この辺はさっぱりなので、後々勉強していったらログ残したいと思います。。
アーキテクチャを作るにあたってのポイント
Airbnbのデータサイエンスのチームによると、下記が大切とのことです。
- 学習ロジックを組むときの前提を疑うことが大切。
- どんなデータを検知・検証したらいいかよくわからない場合は、とにかく全部のデータを残しておくと良い。残しておけば、将来いつでも取り出せる。
- 急成長のスタートアップ企業ではどんどんモデルも変わってくるので、それにロジックをあわせていくことが必要。
下記に参考として元ネタを張りましたが、興味が湧いた方はそちらを参照するとより突っ込んだ内容が書いてあります。自分としては機械学習についてまだまだなので、買い置きしっぱなしだったこの辺の書籍などをまずは読んで勉強ログなどをUPしていければと思います。
[参考]
Architecting a Machine Learning System for Risk - Airbnb Engineering